

# Projects
Projects are the top level of a machine-learning project. It contains datasets, storage providers, annotations and workspaces. These subsections are describe in more detail below.
# Storage Providers
Storage providers are where your files reside. They contain the file that your project will need for its lifecycle. A project have contain multiple storage providers incase your data is separate over different sources or for organizational purposes.
Currently the following storage providers are supported:
- Google Cloud Bucket
- Azure Blob Storage
- AWS S3 Bucket
- Local Server Storage (Enterprise)
If you would like support for other storage providers checkout our open-source library (opens new window) for storage.
# Datasets
Datasets are optional when creating projects. They allow users to group files together. When you import a file (by upload or through the explorer) you can optionally specify a dataset to attach the file too. Files can only be under one dataset.
Datasets are also useful when exporting, as data exports filtered based on the dataset they are attached too.
# Jobs
Labeling Jobs provide a useful management tool. It can help solve the problems of quality assurance, viewing progress and meeting deadlines.
Labeling Jobs allow managers to assign tasks to labelers in order to annotate a group of files. A job contains multiple tasks where each task corresponds to a labeler and each job corresponds to a selection of files.
# Passthroughs
When creating a job a user can specify the number of times a file should be annotated by different labelers. This metrics is called passthroughs. Below is an example of how the passthrough metric divides the files among users.
| Total Files | Number of Labelers | Passthroughs | Distribution |
|---|---|---|---|
| 1000 | 5 | 1 | Each user will annotate 200 files and each file will be view once. |
| 2 | Each user will annotate 400 files and each file will be viewed by 2 labelers. | ||
| 5 | Each user will annotate 100 files and each file will be viewed by all 5 labelers. |
Partial passthroughs can also be specify which can be useful when managers wish for some of the data annotations to have duplicates. This can allow for faster turn around time and partial quality assurance.
# Tasks
A task is assigned to a label which contains files for the labeler to annotate.
# Task File Status Flow
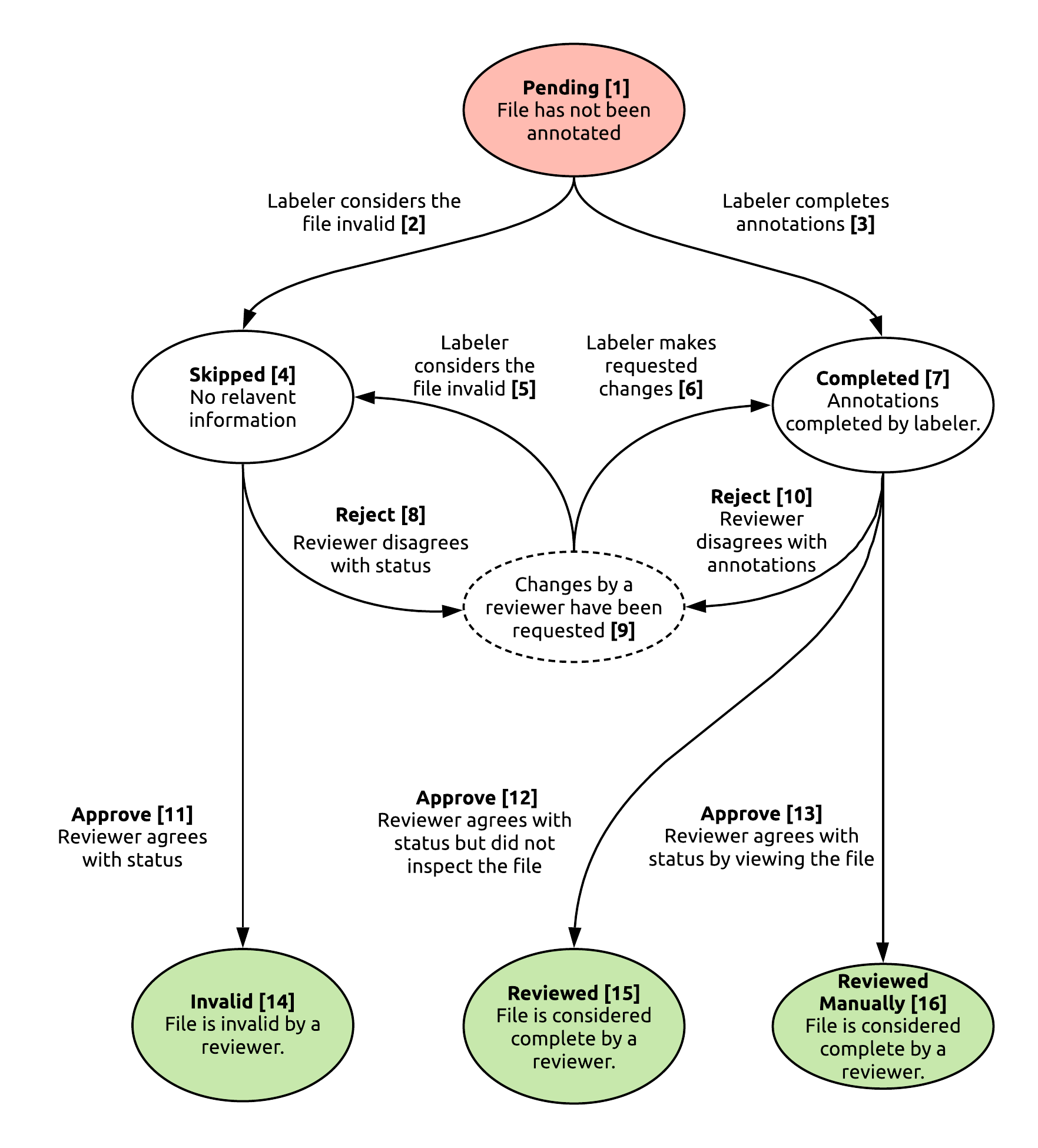
- A file has been added to a task. The labeler may have started annotating but does not consider the file completed.
- The labeler thinks the file does not contain any relevant information.
- The labeler finished all annotations and considers the file complete.
- The labeler thinks the file does not contain any relevant information.
- Labeler changes status to skipped based on reviewers feedback.
- Labeler corrects annotations based on the reviewers feedback.
- The files annotations maybe completed. Waiting for reviewer to approval.
- Reviewer requests the file to be annotated as it contains relevant data.
- Reviewer places comments on the task, annotation, or file to express concerns with annotations.
- The reviewer finds annotations are not correct.
- Reviewer considers file invalid.
- The reviewer does not want to manually look at the rest of the files and marks the rest of the files as completed. This can be set by using the Mask as a approved button or by using consensus.
- The reviewer manually inspects and approves of a files annotations.
- Both reviewer and validator consider file invalid.
- Annotations are completed and approved but were not visually inspected.
- Annotations are completed and approved.