
# Upload data from Google Collab to a Filesource in DataTorch
Take a folder of images in Google Colab, and use DataTorch Python client to upload the files into a cloud storage in a Project's Filesources.
With the Python client, you are able to move images directly from Google Colab into your DataTorch project, with a few simple lines of code.
# Import datatorch
import datatorch
# Assign API and Project to variables and set the api_url parameter to the DataTorch URL
api = datatorch.api.ApiClient(api_key='abcwe34bf-5fe4-41c3-3449-59fb4c25b230', api_url='https://datatorch.io')
proj = api.project(loginOrId = 'r9128c45-fc1b-4333-a5d2-2ea4a35sd9c0')
# Our dataset is 100k images, so we will just upload the first 1000 and do it in batches
first1000 = sorted(os.listdir())[0:1000]
# Iterate through files and run the upload_to_default_filesource command for each of them
import os
for filename in first1000:
file = open(filename,'rb')
api.upload_to_default_filesource(proj,file)
NOTE: Due to limitations in the cloud storage APIs, you are only able to manage 1000 files per folder in cloud storage. Thus, you may need to subdivide folders in your cloud storage so that each one has no more than 1000 files.
# Set up DataTorch
First, make sure you have an existing project created.
Then install the Python client for accessing your project programmatically:
# Install with pip. Requires Python 3. You may need to use pip3
pip install datatorch
# Authenticate Access
DataTorch uses API keys to authenticate the client. API keys are generated in your account settings (opens new window) which you can access by clicking the user icon in the upper right hand corner.
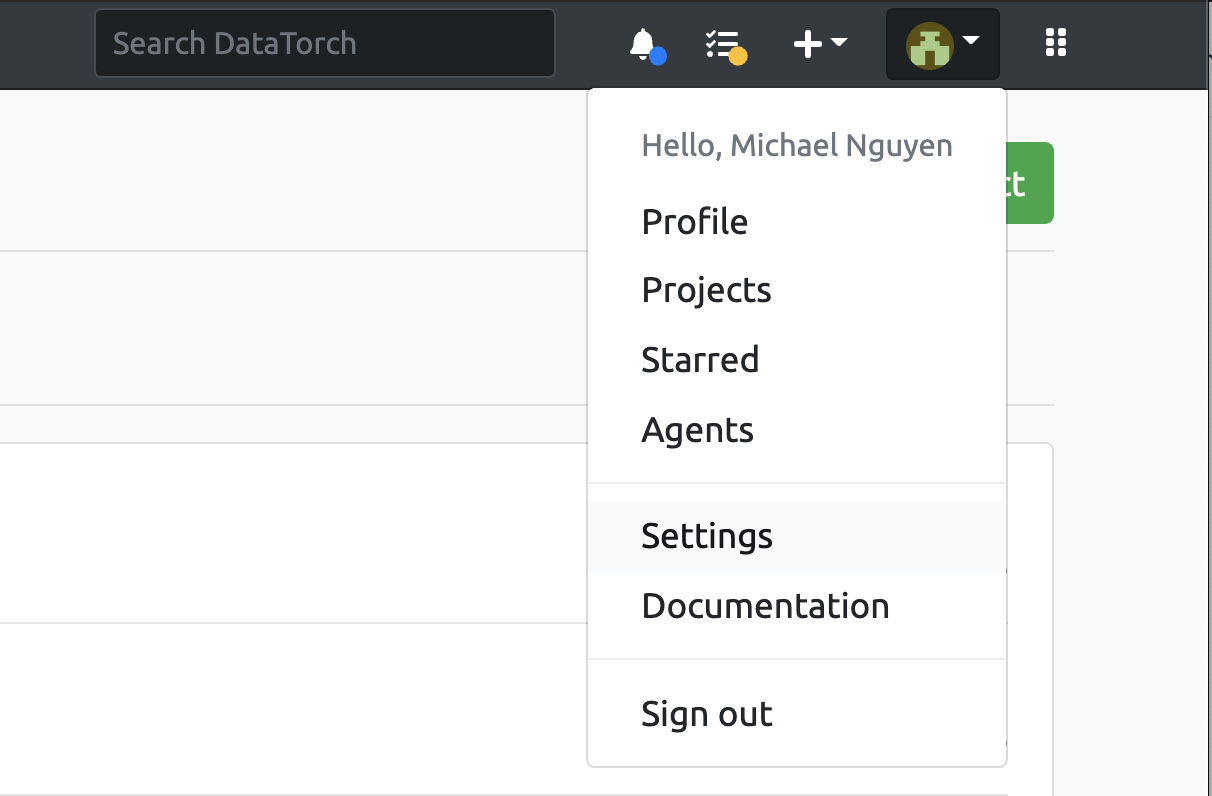
Afterwards, click on "Access Tokens", then "New Key". Enter a name for your key then click "Create" to generate a new key.
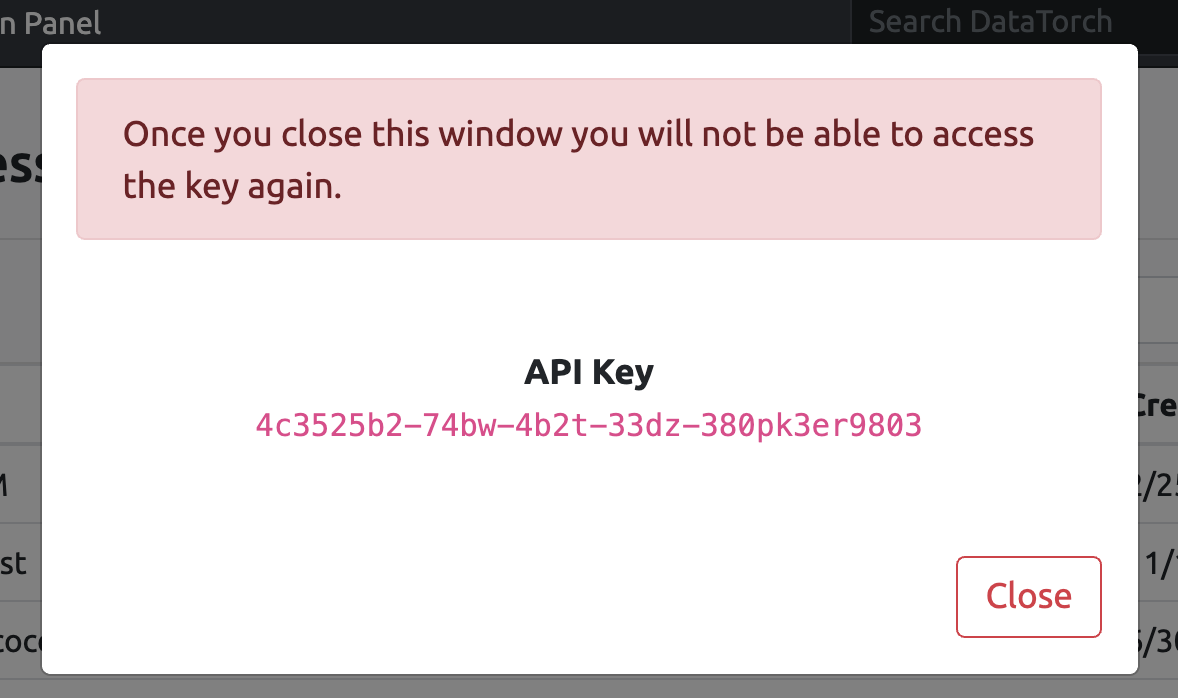
# Get Project ID
In order to upload data to your project, you will need the project ID, which is found in the settings section of your project:
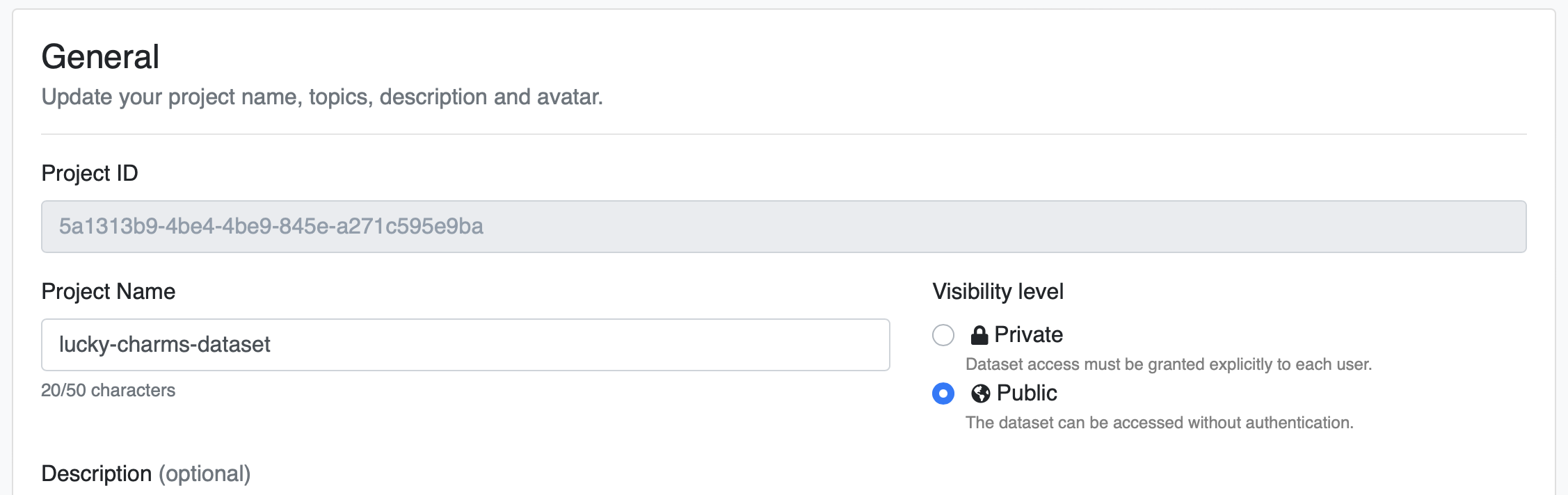
# Example Script
Currently, the Python client only allows upload to the default DataTorch Storage. Use the upload_to_default_filesource() function to do so:
# Import datatorch
import datatorch
# Assign API and Project to variables and set the api_url parameter to the DataTorch URL
api = datatorch.api.ApiClient(api_key='abcwe34bf-5fe4-41c3-3449-59fb4c25b230', api_url='https://datatorch.io')
proj = api.project(loginOrId = 'r9128c45-fc1b-4333-a5d2-2ea4a35sd9c0')
# Our dataset is 100k images, so we will just upload the first 1000 and do it in batches
first1000 = sorted(os.listdir())[0:1000]
# Iterate through files and run the upload_to_default_filesource command for each of them
import os
for filename in first1000:
file = open(filename,'rb')
api.upload_to_default_filesource(proj,file)